MoMatch - Multilingual Ontology Matching
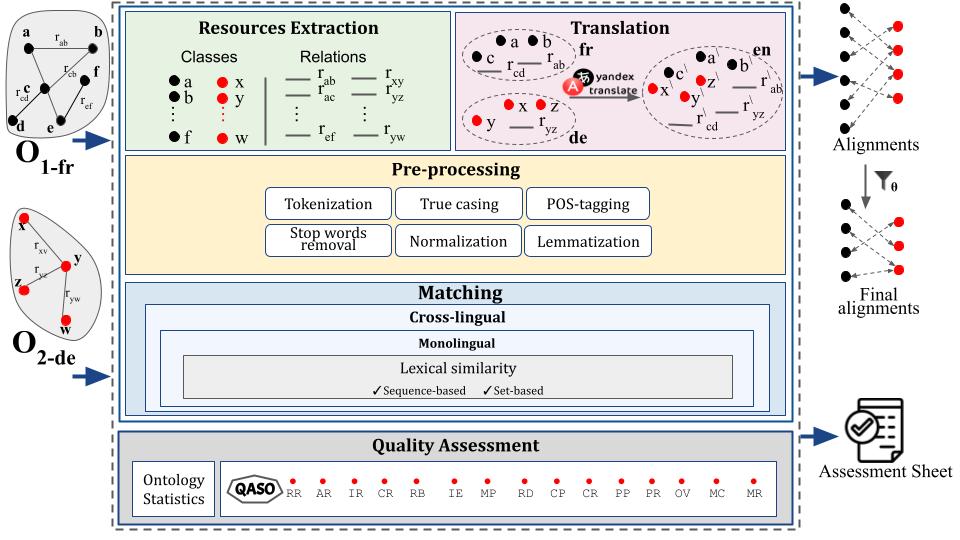
MoMatch is an approach for matching ontologies in different natural languages. MoMatch uses machine translation and various string similarity techniques to identify correspondences across different ontologies. MoMatch uses the Quality Assessment Suite for Ontologies QASO that comprises 15 metrics in which eight metrics for assessing the quality of the matching process and seven for assessing ontologies quality.
The following figure shows MoMatch’s architecture:
The input is two ontologies which can be either in two different natural languages or in the same language. The output is the alignments between the input ontologies in addition to the assessment sheet for the input ontologies and the resultant alignment.
MoMatch is comprised of four phases:
The latest code is available in a public repository in GitHub. A description for each configurable parameter and function can be found here.
All implementations are based on Scala 2.11.11 and Apache Spark 2.3.1.. After installing them, download MoMatch using:
After you are done with the configurations mentioned above, you will be able to open the project. The following figure shows MoMatch in IntelliJ.
You can start with running the MoMatchGUL.scala class to open the GUI (as shown in figure 3).
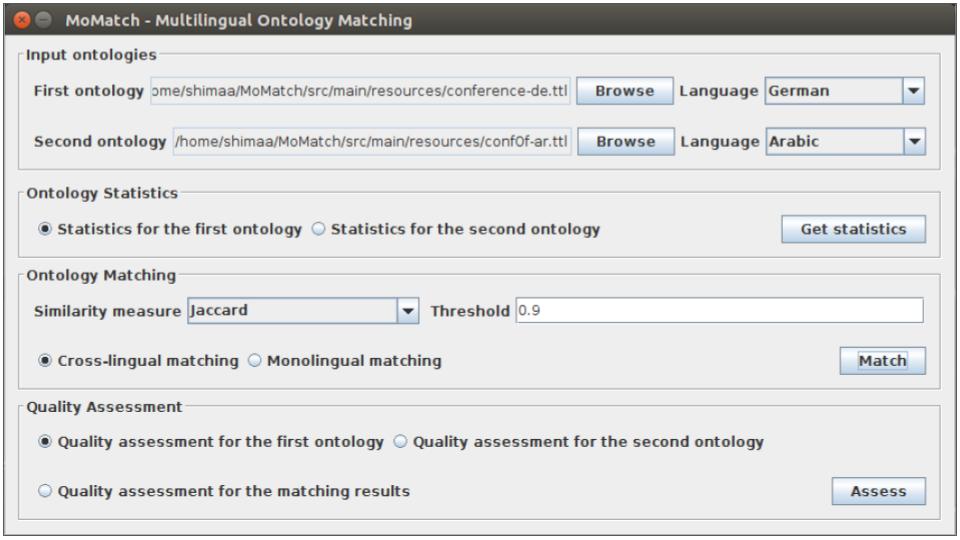
The following example scenario describes the matching process of the two ontologies: Conference and ConfOf in German and Arabic respectively, from the MultiFarm dataset, in addition to the quality assessment for the ontologies and the matching results. First, the user selects the two ontologies, in Turtle, and their languages. MoMatch reads the two input ontologies and generates RDD representation of them. MoMatch uses SANSA-RDF library with Apache Jena framework to parse and manipulate the input ontologies (as RDF triples) in a distributed manner. The user can get statistics about the input ontologies as follows:
First ontology name is: conference-de
Second ontology name is: confOf-ar
===============================================
| Statistics for the first ontology |
===============================================
Number of all resources = 105"
Number of triples in the ontology = 509
Number of object properties is 46
Number of annotation properties is 1
Number of Datatype properties is 18
Number of classes is 60.0
===============================================
| Statistics for the second ontology |
===============================================
Number of all resources = 52"
Number of triples in the ontology = 321
Number of object properties is 13
Number of annotation properties is 1
Number of Datatype properties is 23
Number of classes is 38.0
Matching type is: Cross-lingual matching
Language for the first ontology is:German
Language for the second ontology is:Arabic
===============================================
| Matched classes |
===============================================
(Organisation,Organization,منظمة,Organization,1.0)
(Tutorium,Tutorial,البرنامج التعليمي,Tutorial,1.0)
(eingereichter Beitrag,any contribution,مساهمة,The contribution of,1.0)
(Thema,Topic,الموضوع,Topic,1.0)
(Workshop,Workshop,ورشة عمل,Workshop,1.0)
(Konferenz,Conference,مؤتمر,conference,1.0)
Number of matched classes = 6
===============================================
| Matched properties |
===============================================
(hat Vornamen,has a first name,لديه الاسم الأول,have the first name,1.0)
(hat Nachnamen,has last name,لديه اللقب,Has the last name,1.0)
(hat Zusammenfassung,has summary,لديه ملخص,Has a summary,1.0)
Number of matched relations = 3
===============================================
| Quality assessment for the first ontology |
===============================================
Relationship richness for O is 0.48
Attribute richness for O is 0.78
Inheritance richness for O is 0.83
Readability for O is 1.17
Isolated Elements for O is 0.11
Missing Domain Or Range for O is 0.02
Redundancy for O is 0.0
===============================================
| Quality assessment for the second ontology |
===============================================
Relationship richness for O is 0.28
Attribute richness for O is 0.33
Inheritance richness for O is 0.85
Readability for O is 1.44
Isolated Elements for O is 0.07
Missing Domain Or Range for O is 0.03
Redundancy for O is 0.0
===============================================
| Quality assessment for the matching results |
===============================================
Degree of overlapping is 6.0%
Match coverage is 0.11
Match ratio is 1.0