MULON - MULtilingual Ontology mergiNg
MULON is an approach, for merging monolingual ontologies in different natural languages producing a multilingual ontology. In a multilingual ontology, resources (classes and properties) can be published in a language-independent way, associated with language-dependent (linguistic) information, which supports access across various natural languages. Merging means creating a single ontology to provide a unified view of the input ontologies by maintaining all information contained in them.
There are two types of ontology merging: a) Symmetric merging; which aims to integrate all resources (classes and properties) in the input ontologies to a single ontology, i.e. preserves all input resources (which is used in MULON), and b) Asymmetric merging; which considers one of the input ontologies as the target ontology and merges the remaining non-redundant resources of the input ontologies into the target ontology.
The creation of such ontology is a complex task and requires considerable adaptation and rigorous techniques to control various steps of the creation, especially when merging ontologies in different natural languages. Identification of mappings between multilingual input ontologies, the first step in the merging process, plays a vital role in the ontology merging process.
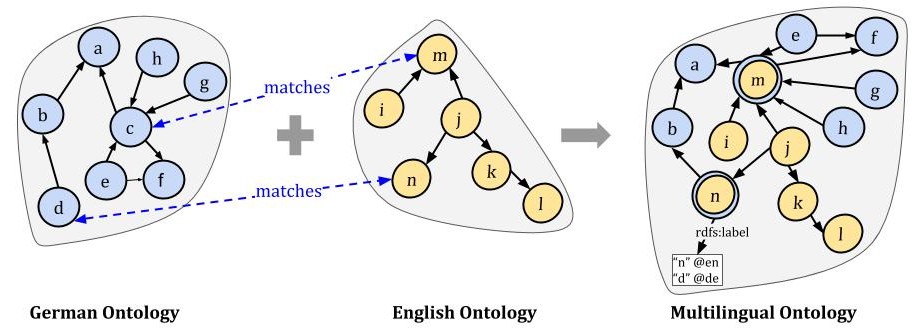
As an illustration example, first, MULON identifies cross-lingual matches between input ontologies using cross-lingual matching techniques, then adds them to the merged multilingual ontology by adding rdfs:label for each language (using language-tagged strings) as shown in Figure 1.
Cross-lingual matching helps to lower redundancy in the merged ontology.
The following figure shows MULON’s architecture:
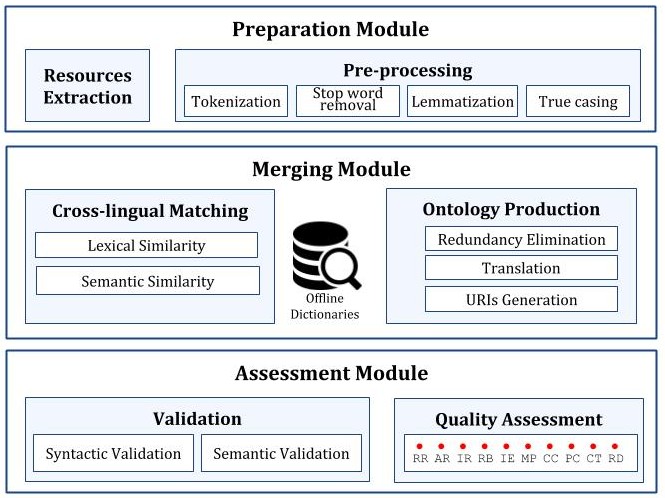
The input to MULAN is the two ontologies in two different natural languages. The output is a multilingual in addition to an assessment sheet presenting the quality of the merged ontology.
MULON is comprised of three modules:
The latest code is available in a public repository in GitHub. A description for each configurable parameter and function can be found here.
All implementations are based on Scala 2.11.11 and Apache Spark 2.3.1.. After installing them, download MULON using:
After you are done with the configurations mentioned above, you will be able to open the project. The following figure shows MULON in IntelliJ
The following example describing merging two ontologies: Conference ontology in German (O1), from the MultiFarm dataset, and the Scientific Events Ontology in English (O2). First, MULON reads the two input ontologies in Turtle (line 1 and 2) and convert them into N-Triples format and generates RDD representation of them (line 4 and 5). MULON uses SANSA-RDF library with Apache Jena framework to parse and manipulate the input ontologies (as RDF triples) in a distributed manner. SANSA support different RDF serialization formats (e.g. NTRIPLES/N3, XML/RDF, TURTLE, QUAD). Second, MULON generates the multilingual merged ontology (line 6) and gets its statistics (line 9) such as number of classes, number of object properties, number of annotation properties, and number of datatype properties. Finally, MULON creates the assessment sheet for the input and output ontologies (line 12).
val O1 = ".../conference-de.ttl"
val O2 = ".../SEO.ttl"
val lang = Lang.NTRIPLES
val O1triples: RDD[graph.Triple] = spark.rdf(lang)(O1)
val O2triples: RDD[graph.Triple] = spark.rdf(lang)(O2)
val multilingualMergedOntology: RDD[graph.Triple] = ontoMerge.MergeOntologies(O1triples, O2triples)
val ontStat = new OntologyStatistics(sparkSession1)
println("Statistics for merged ontology")
ontStat.GetStatistics(multilingualMergedOntology)
//Assessemnt sheet
val quality = new QualityAssessment(sparkSession1)
quality.GetQualityAssessmentSheet(O1triples, O2triples, multilingualMergedOntology)
A sample output for the merged ontology, in N-Triples format, is presented in the following script where every resource has English and German labels. For example "ConferenceProceedings" is a class with the German label "Fortschritte der konferenz".
Quality assessment sheet for the input and merged ontologies where O1 is the Conference ontology in German, O2 is the SEO ontology in English, and Om is the multilingual merged ontology.